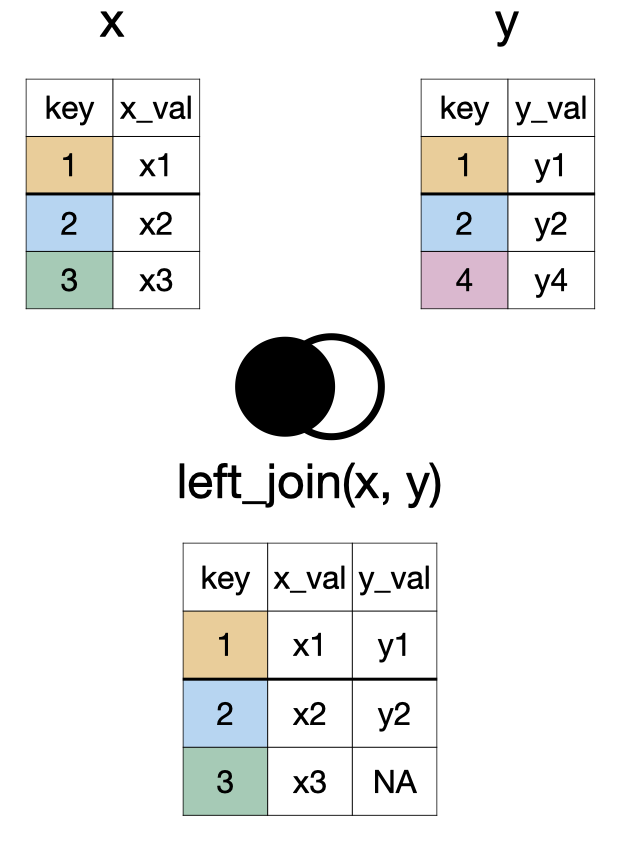
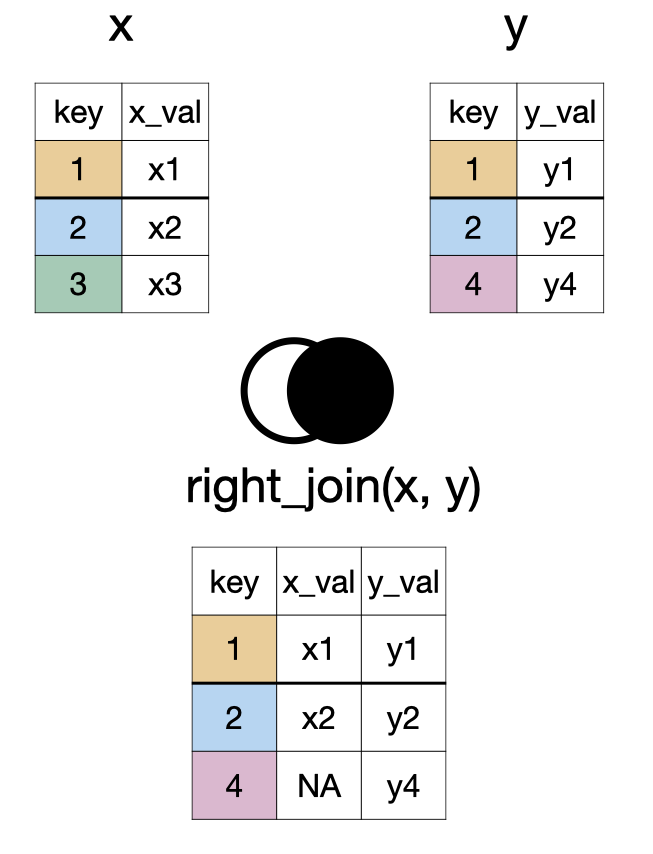
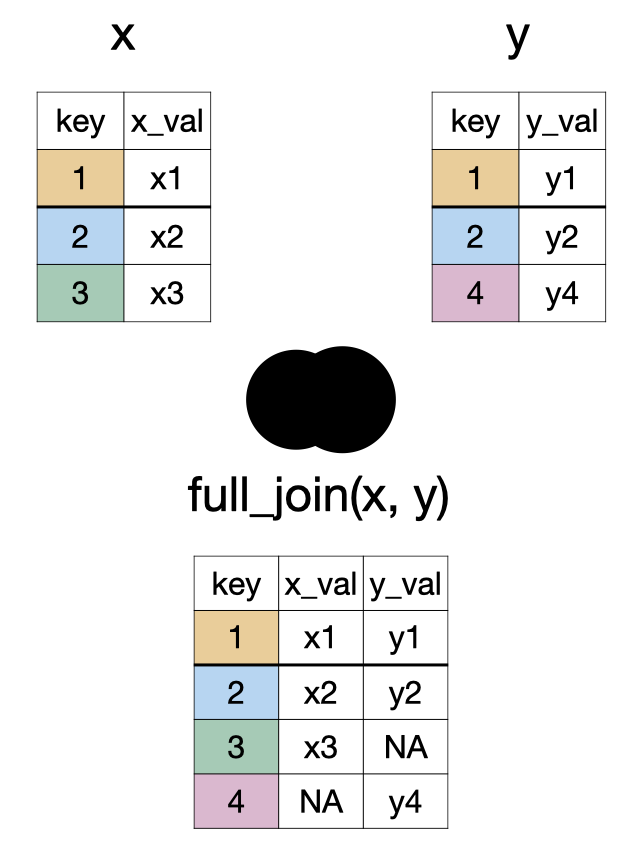
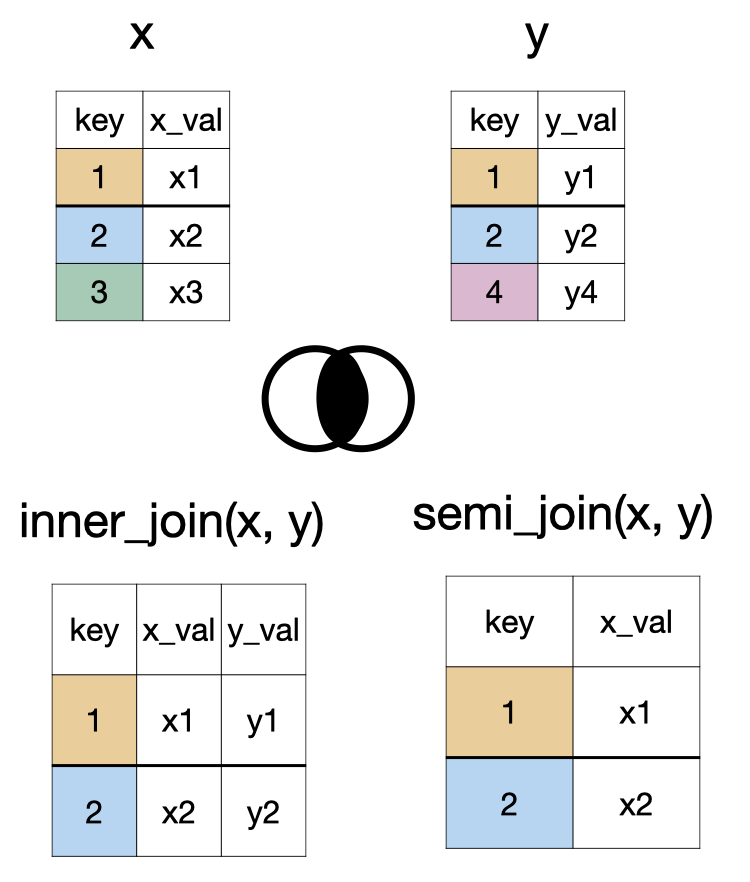
glimpse(lapd)Rows: 14,824
Columns: 4
$ job_class_title <fct> Police Detective II, Police Sergeant I, Police Lieuten…
$ employment_type <fct> Full Time, Full Time, Full Time, Full Time, Full Time,…
$ base_pay <dbl> 119321.60, 113270.70, 148116.00, 78676.87, 109373.63, …
$ base_pay_level <chr> "Greater than 100K", "Greater than 100K", "Greater tha…