
Introduction to Frequentist Inference
Inference for a Proportion
Dr. Mine Dogucu
Bayesian vs. Frequentist Inference
Bayesian
P (Hypotheses | Data) Hypotheses have probabilities in light of the observed data
Frequentist
P (Data | Hypotheses)
Data have probability considering the conditions of the hypotheses
Credible Intervals
Confidence Intervals
Recall Bayesian Inference - Posterior Model
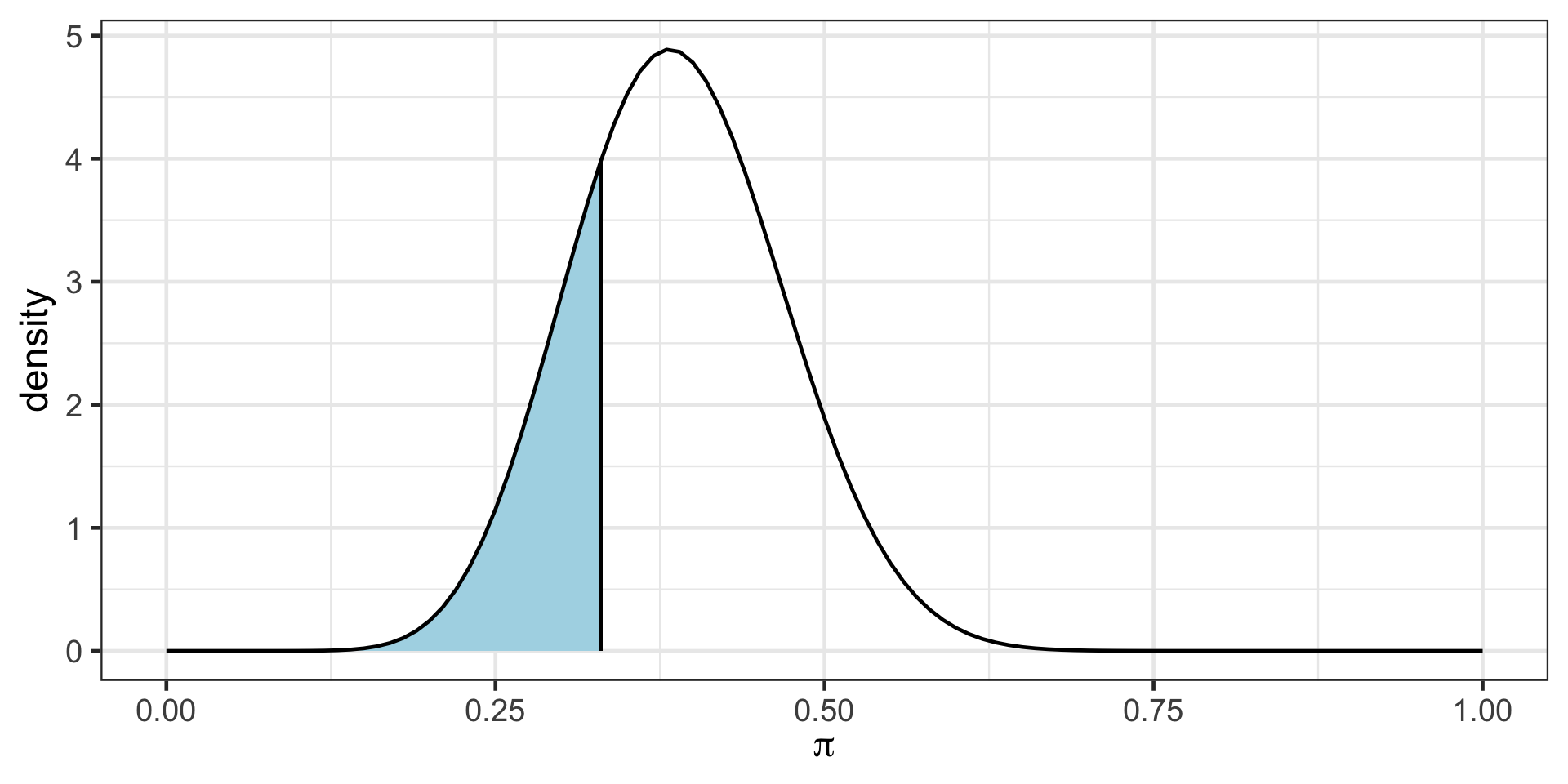
Bayesian vs. Frequentist Inference
In the previous example we could talk about probability of the parameter.
For instance \(P(\pi<0.33 | y)\), in other words probability of the parameter being less than 0.33 given that we have observed data (9 out of 20 movies passed).
In frequentist inference we will talk about probability of data given some parameter value.
Data Context
as seen in Chance, B. L., & Rossman, A. J. (2006). Investigating statistical concepts, applications and methods
Experiment
Babies are watching a video with a helper or hinderer shape.
Then they are asked to pick a shape.
Data
14 out of 16 infants (10-months old) have chosen the helper shape. What are some possible explanations of this?
Write down
Write down all possible ideas that you can think of with your neighbor.
Possible Explanations
Study Design
- Color of the toy
- Right vs. left
- Shape of the toy
Hypothesis
- 10 months old babies are socially developed
Hypothesis
- 10 months old babies are making a random choice
Hypotheses Testing
Hypotheses To Test
Babies are making a random choice
Babies are not making a random choice
Hypotheses To Test
\(H_0\): Babies are making a random choice
\(H_a\): Babies are not making a random choice
Hypotheses To Test
\(H_0\): Babies are making a random choice
\(H_a\): Babies are not making a random choice
Which of these is easier to model right now?
Hypotheses To Test
\(H_0\): Babies are making a random choice (\(\pi = 0.5\))
\(H_a\): Babies are not making a random choice (\(\pi \neq 0.5\))
Assumption
Let’s assume that babies are making a random choice
Out of 16 babies, how many babies would you expect to choose the helper shape?
Could this number be 7? In other words, if babies were making random choices, would you be surprised to see 7 babies choose the helper shape?
- Could this number be 11?
- Could this number be 3?
- Could this number be 14?
Surprise threshold
What is your surprise threshold? Below and above which number would you start getting surprised?
Surprise threshold
What is your surprise threshold? Below and above which number would you start getting surprised?
Surprise threshold
What is your surprise threshold? Below and above which number would you start getting surprised?
Simulate data
With your neighbor, flip a coin 16 times and record the number of heads that you observe. In other words, each group is a set of researchers observing the behavior of 16 babies from Randomville.
Plot class data
Conclusions
Hypotheses Babies are making a random choice Babies are not making a random choice
Do you agree with the authors claim “These findings constitute evidence that preverbal infants assess individuals on the basis of their behaviour towards others”? Why? Why not? Do the findings generalize to all infants?
Surprise (extreme threshold)
Instead of count of babies, we will often see surprise threshold set at 0.05 probability. This is a debatable topic what the surprise threshold should be.
If the sample observation is in the 0.05 highlighted region, then we would be “surprised”. In other words, if the sample is in the 0.05 highlighted region, then we would conclude that there is a low probability of observing a surprising sample like this one or something more extreme if the randomness model were true.
Surprise (extreme threshold)
- If the randomness model were true, there would be a low probability (less than 0.05) of observing a sample value like the one we have observed or something more extreme. So, we reject the randomness model (null hypothesis) and conclude the alternative model.
p-value
A p-value is the probability of obtaining your observed results or something even more extreme assuming that the null hypothesis is correct.
Error
- Could we have possibly made an error?
- We rejected the randomness model. Let’s assume for a second that it were true, could we have observed 14 babies (or something more extreme) choosing the helper shape?
- Yes!!! Low probability but still possible.
- If the randomness model were true and we rejected it, we made a Type 1 Error (𝛼)!!!
- We often set 𝛼 = 0.05 (debatable).
Confidence Intervals
From Testing to Estimation
We just tested the “Randomness Model” (\(\pi = 0.5\)) and found 14/16 babies was very surprising. We rejected the idea that they were just guessing.
But that only tells us what the proportion isn’t.
If the true proportion of all babies who prefer the helper isn’t 0.5, what is it?
- Is it 0.70?
- Is it 0.85?
- Is it 0.99?
Confidence Intervals
Confidence Intervals help us move from a single “Yes/No” test to a range of plausible values for our parameter.
What is “Plausible”?
Recall our Surprise Threshold. We get “surprised” if our data is too far away from what a model predicts.
Imagine testing every possible value for \(\pi\) (the true proportion) from 0 to 1:
- If we assumed \(\pi = 0.6\), would 14/16 be surprising? (Probably)
- If we assumed \(\pi = 0.8\), would 14/16 be surprising? (Probably not)
Confidence Intervals
A Confidence Interval is simply the collection of all values that would NOT make us surprised if we tested them as the null hypothesis. You can think of it as the “non-surprise” range for \(\pi\).
Catching the Parameter
In Frequentist inference, the true population proportion (\(\pi\)) is a fixed value. It is like a fish sitting still in the ocean.
- A Point Estimate (14/16 = 0.875) is like trying to hit the fish with a spear. It’s hard to be exactly right!
- A Confidence Interval is like throwing a net.
For our 16 infants, the 95% Confidence Interval is (0.617, 0.984).
We are 95% confident that the true proportion of babies who prefer the helper shape is between 61.7% and 98.4%. This is NOT a probability.
Interpretation
The “Confidence Level” (95%) is a property of the net’s design.
If we go fishing 100 times with this net, we expect that 95 of those times, the net will be wide enough and positioned well enough to catch the fish.
If we take a sample 100 times from the population over and over again, construct a confidence interval using each of the sample data, we would expect 95% of the confidence intervals to contain the true/unknown parameter value of \(\pi\).
Interpretation
Once we calculate our interval for the 16 babies, the interval is fixed. The true proportion is also fixed.
Incorrect: “There is a 95% probability that the true proportion is in this specific interval.” Remember we can make probabilistic judgments about the parameter in Bayesian framework - not frequentist.
Correct: “We used a method that is, in the long run, expected to capture the true proportion 95% of the time successfully.”