GitHub repos
No repo this week. Time for you to create your own repos under your own username. Make sure to set them to be private.
(Normal) Linear Regression Response Variables
Birth weight of Babies (55 - 176 ounces)
Sale Prices ($12789 - $755,000)
Number of Species (6 - 129 mammals)
Logistic Regression Response Variables
Will it rain tomorrow? (Yes/No)
Is email spam? (Yes/No)
Does the candidate receive a callback? (Yes/No)
When the response variable is binary a logistic regression model can be utilized.
Data source
Researchers respond to help-wanted ads in Boston and Chicago newspapers with fictitious resumes.
They randomly assign White sounding names to half the resumes and African American sounding names to the other half.
They create high quality resumes (more experience, likely to have an email address etc.) and low quality resumes.
For each job ad they send four resumes (two high quality and two low quality.)
Data
<- resume |> select (received_callback, race, years_experience, glimpse (resume)
Rows: 4,870
Columns: 4
$ received_callback <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FAL…
$ race <chr> "white", "white", "black", "black", "white", "white"…
$ years_experience <int> 6, 6, 6, 6, 22, 6, 5, 21, 3, 6, 8, 8, 4, 4, 5, 4, 5,…
$ job_city <chr> "Chicago", "Chicago", "Chicago", "Chicago", "Chicago…
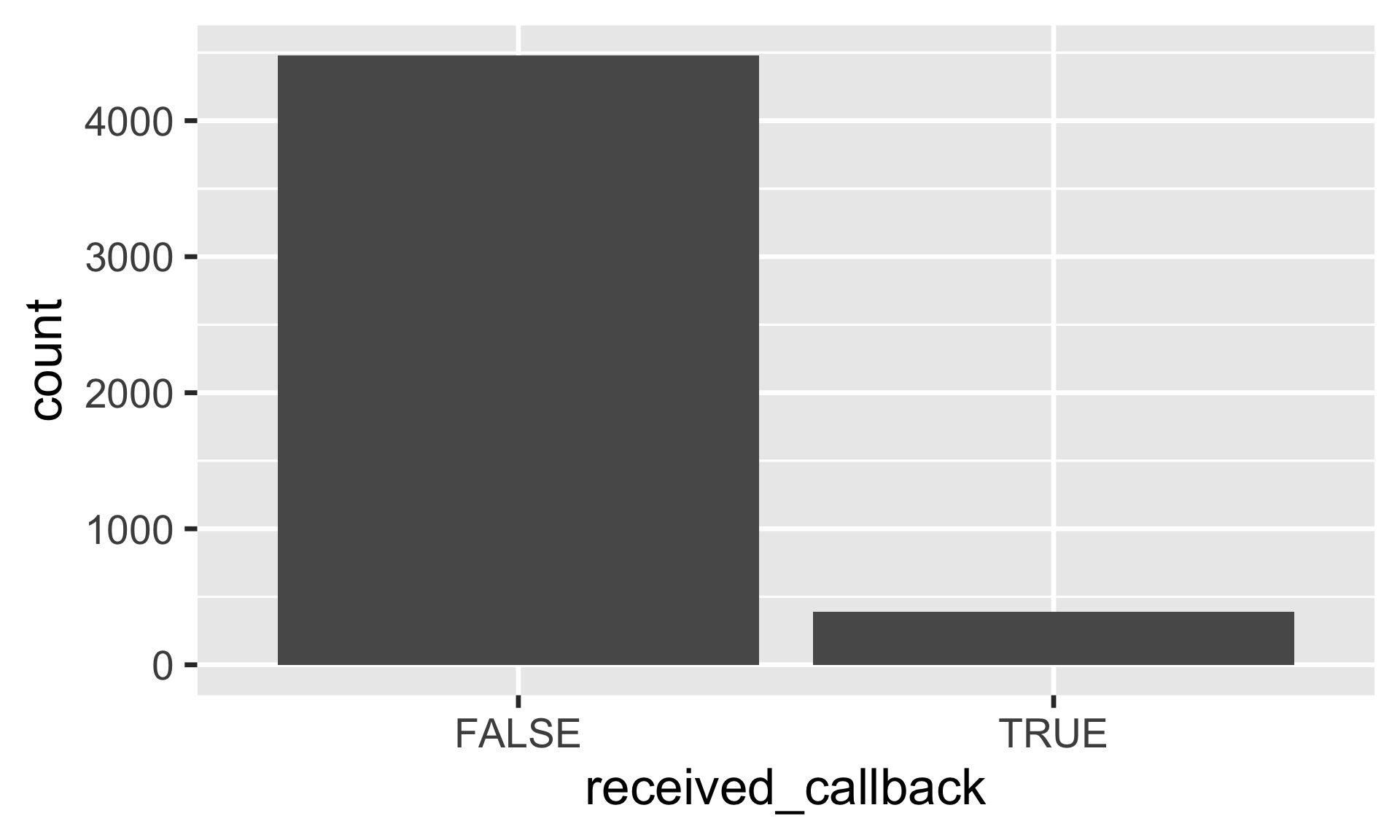
Response variable: received_callback
count (resume, received_callback) |> mutate (prop = n / sum (n))
# A tibble: 2 × 3
received_callback n prop
<lgl> <int> <dbl>
1 FALSE 4478 0.920
2 TRUE 392 0.0805
Notation
\(y_i\) = whether a (fictitious) job candidate receives a call back.
\(\pi_i\) = probability that the \(i\) th job candidate will receive a call back.
\(1-\pi_i\) = probability that the \(i\) th job candidate will not receive a call back.
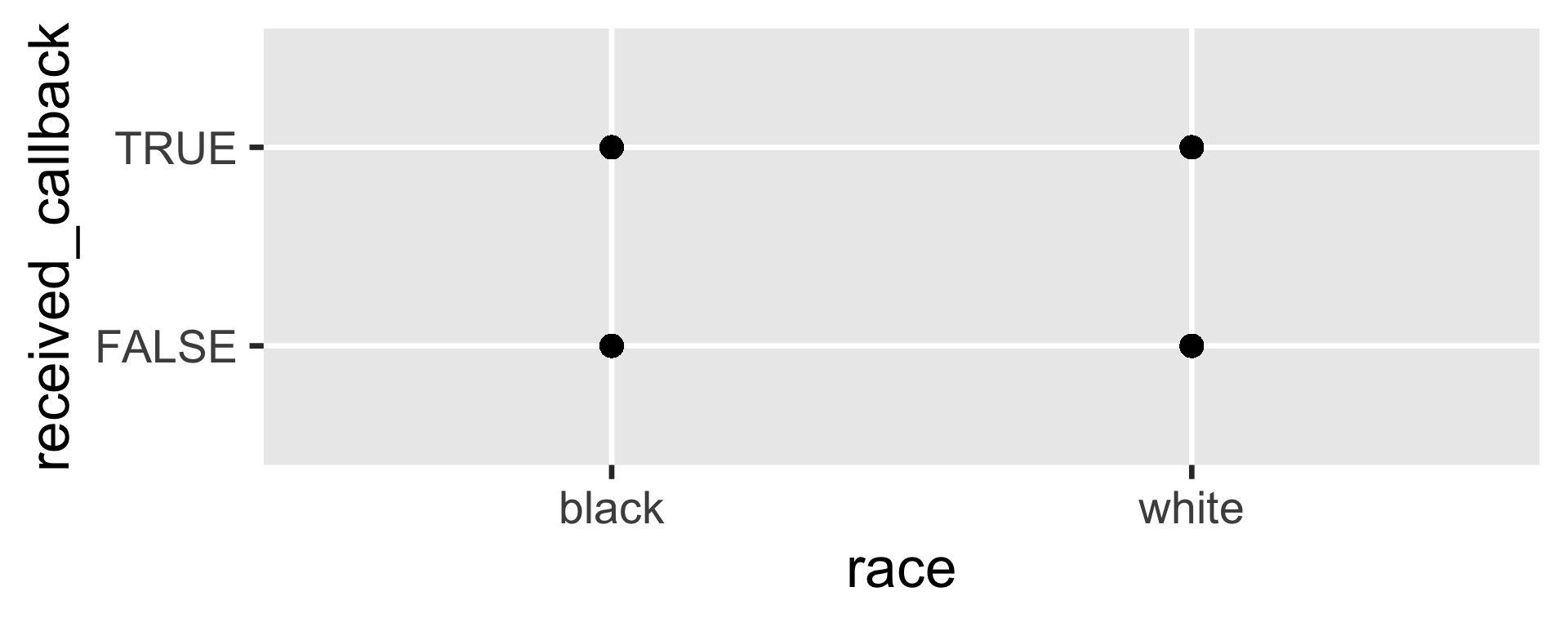
Where is the line?
ggplot (resume, aes (x = race, y = received_callback)) + geom_point ()
The Linear Model
We can model the probability of receiving a callback with a linear model.
\(\text{transformation}(\pi_i) = \beta_0 + \beta_1x_{1i}+\beta_2x_{2i} +.... \beta_kx_{ki}\)
\(logit(\pi_i) = \beta_0 + \beta_1x_{1i}+\beta_2x_{2i} +.... \beta_kx_{ki}\)
\(logit(\pi_i) = log(\frac{\pi_i}{1-\pi_i})\)
Note that log is natural log and not base 10. This is also the case for the log() function in R.
Probability, Odds, and Logit
Probability \(\pi_i\) Probability of receiving a callback.
Odds \(\frac{\pi_i}{1-\pi_i}\) Odds of receiving a callback.
Logit \(log(\frac{\pi_i}{1-\pi_i})\) Logit of receiving a callback.
Proportion as outcome
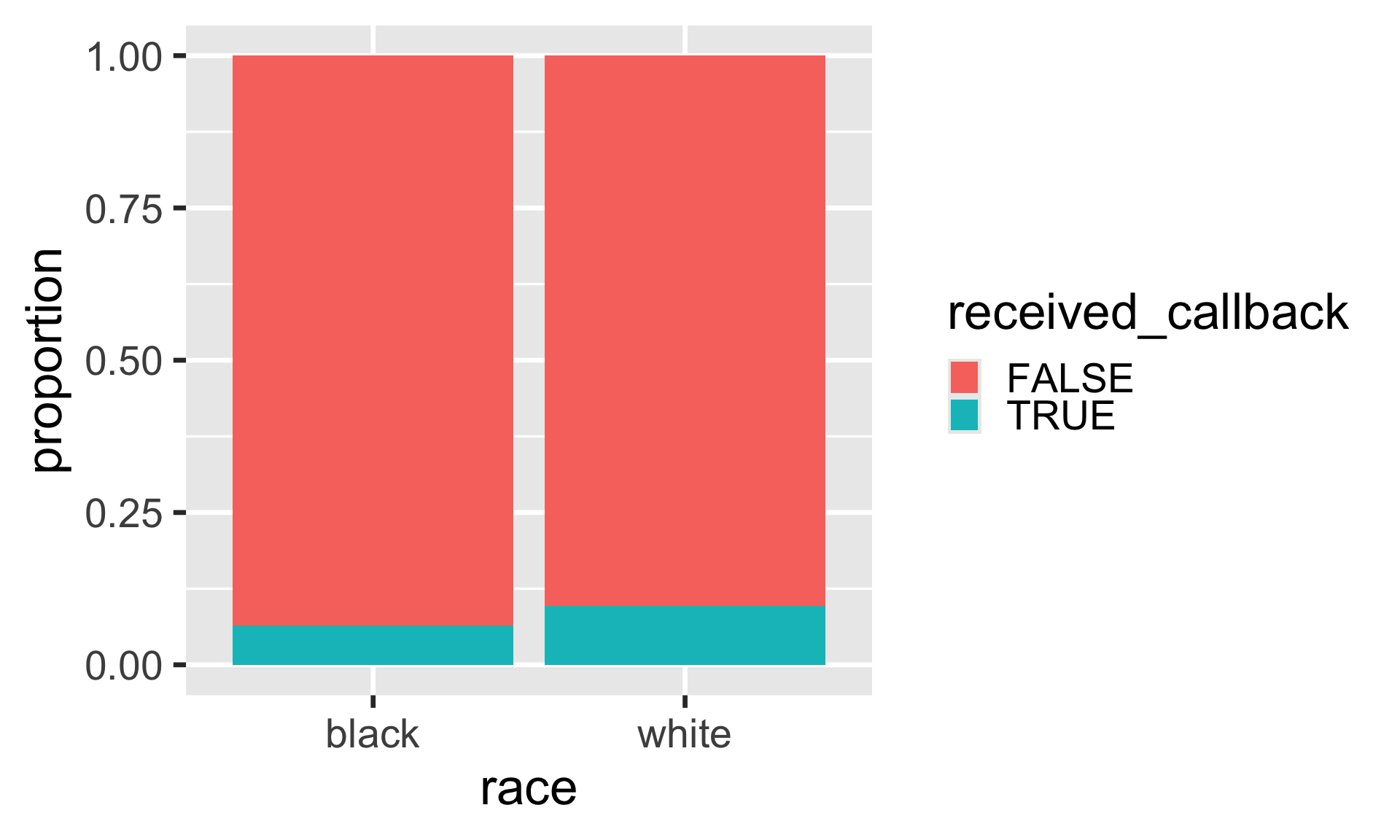
When race is black (0)
|> filter (race == "black" ) |> count (received_callback) |> mutate (prop = n / sum (n))
# A tibble: 2 × 3
received_callback n prop
<lgl> <int> <dbl>
1 FALSE 2278 0.936
2 TRUE 157 0.0645
Note that R assigns 0 an 1 to levels of categorical variables in alphabetical order. In this case black (0) and white(1)
When race is black (0)
<- resume |> filter (race == "black" ) |> count (received_callback) |> mutate (prop = n / sum (n)) |> filter (received_callback == TRUE ) |> select (prop) |> pull ()
Probability of receiving a callback when the candidate has a Black sounding name is 0.0644764.
When race is white (1)
<- resume |> filter (race == "white" ) |> count (received_callback) |> mutate (prop = n / sum (n)) |> filter (received_callback == TRUE ) |> select (prop) |> pull ()
Probability of receiving a callback when the candidate has a white sounding name is 0.0965092.
Probability, Odds, and Logit
## Odds <- p_b / (1 - p_b)## Logit <- log (odds_b)
Probability, Odds, and Logit
## Odds <- p_b / (1 - p_b)## Logit <- log (odds_b)
## Odds <- p_w / (1 - p_w)## Logit <- log (odds_w)
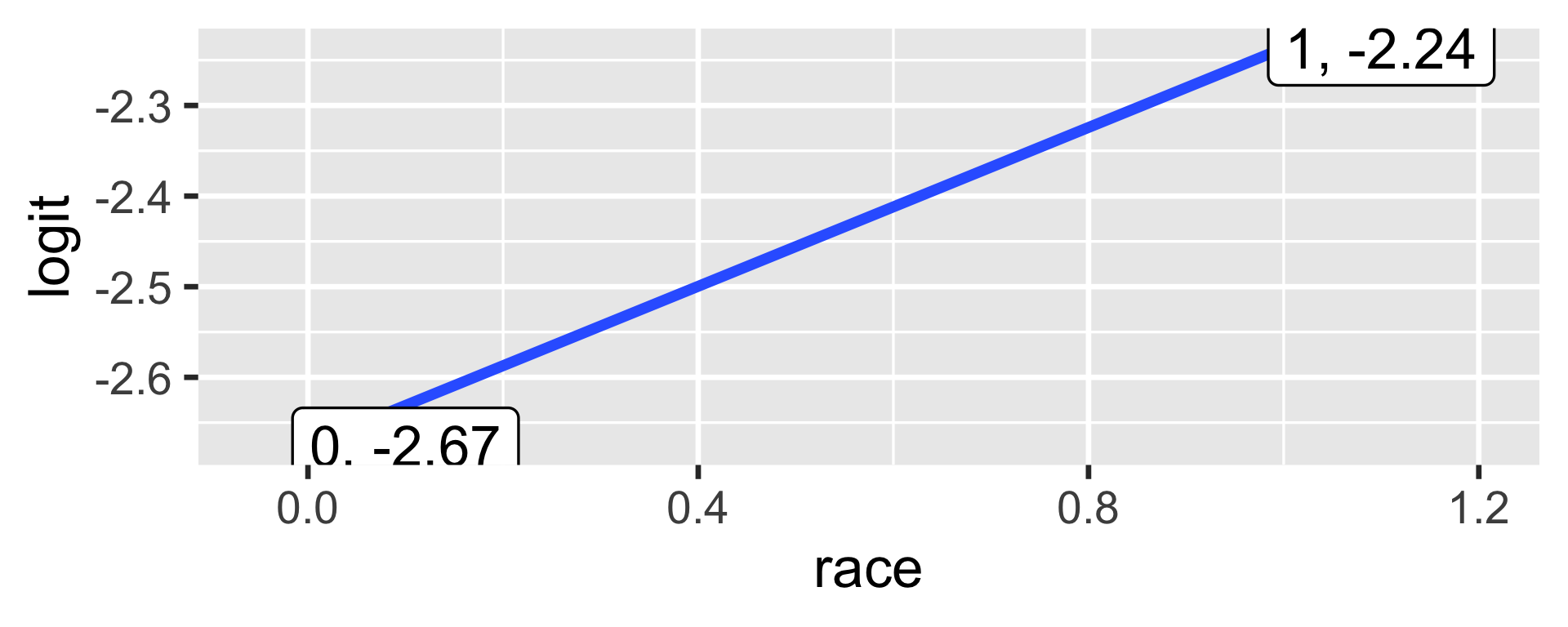
Estimates
This is THE LINE of the linear model. As x increases by 1 unit, the expected change in the logit of receiving call back is 0.4381802.
The slope of the line is:
The slope is the difference between logit for the white group and the black group.
The intercept is
Linear Equation
<- glm (received_callback ~ race,data = resume,family = binomial)
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -2.67 0.0825 -32.4 1.59e-230
2 racewhite 0.438 0.107 4.08 4.45e- 5
\(log(\frac{\hat \pi_i}{1-\hat \pi_i}) = -2.67 + 0.438\times racewhite_i\)
Conversion
Probability
0 to 1
Odds
0 to \(\infty\)
Logit
- \(\infty\) to \(\infty\)
Generalized Linear Model in R
We will consider years of experience as an explanatory variable. Normally, we would also include race in the model and have multiple explanatory variables, however, for learning purposes, we will keep the model simple.
<- glm (received_callback ~ years_experience,data = resume,family = binomial)
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -2.76 0.0962 -28.7 5.58e-181
2 years_experience 0.0391 0.00918 4.26 2.07e- 5
Model Summary
<- tidy (model_y)<- model_y_summary |> filter (term == "(Intercept)" ) |> select (estimate) |> pull ()<- model_y_summary |> filter (term == "years_experience" ) |> select (estimate) |> pull ()
From logit to odds
Logit for a Candidate with 1 year of experience (rounded equation)
\(-2.76 + 0.0391 \times 1\)
Odds for a Candidate with 1 year of experience
\(odds = e^{logit}\)
\(\frac{\pi_i}{1-\pi_i} = e^{log(\frac{\pi_i}{1-\pi_i})}\)
\(\frac{\hat\pi_i}{1-\hat\pi_i} = e^{-2.76 + 0.0391 \times 1}\)
From odds to probability
\(\pi_i = \frac{odds}{1+odds}\)
\(\pi_i = \frac{\frac{\pi_i}{1-\pi_i}}{1+\frac{\pi_i}{1-\pi_i}}\)
\(\hat\pi_i = \frac{e^{-2.76 + 0.0391 \times 1}}{1+e^{-2.76 + 0.0391 \times 1}} = 0.0618\)
Note you can use exp() function in R for exponentiating number e.
3 predictors
<- glm (received_callback ~ race + + job_city,data = resume,family = binomial)
Model results
# A tibble: 4 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -2.78 0.134 -20.8 6.18e-96
2 racewhite 0.440 0.108 4.09 4.39e- 5
3 years_experience 0.0332 0.00940 3.53 4.11e- 4
4 job_cityChicago -0.329 0.108 -3.04 2.33e- 3
Interpretation
The estimated probability that a Black candidate with 10 years of experience, residing in Boston, would receive a callback.
\(\large{\hat\pi_i = \frac{e^{-2.78 + (0.0440 \times 0) + (0.0332\times10) + (-0.0329\times 0)}}{1+e^{-2.78 + (0.0440 \times 0) + (0.0332\times10) + (-0.0329\times 0)}}}\)
\(= 0.0796\)
Model Evaluation
<- babies |> mutate (low_bwt = case_when (bwt < 88 ~ TRUE ,>= 88 ~ FALSE )) |> drop_na (gestation)
Model Gestation
<- glm (low_bwt ~ gestation, data = babies,family = "binomial" )
Model Results
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 17.5 2.24 7.82 5.11e-15
2 gestation -0.0758 0.00846 -8.96 3.27e-19
\(\hat p = \frac{\exp(b_0 +b_1x)}{1+\exp(b_0 + b_1x)}\)
\(\hat p\) when gestation is 284 = \(\frac{\exp(17.5 -0.0758 \cdot 284)}{1+\exp(17.5 -0.0758 \cdot 284)} = \frac{\exp(-4.0272)}{1+ \exp(-4.0272)} = 0.01751203\)
Add predictions
<- babies |> add_predictions (model_g) select (babies, pred)
# A tibble: 1,223 × 1
pred
<dbl>
1 -4.02
2 -3.87
3 -3.64
4 -3.87
5 -4.17
6 -0.986
7 -1.06
8 -4.40
9 -5.15
10 -9.10
# ℹ 1,213 more rows
Predictions in probability scale
<- babies |> mutate (pred_p = exp (pred)/ (1 + exp (pred)))select (babies, pred, pred_p)
# A tibble: 1,223 × 2
pred pred_p
<dbl> <dbl>
1 -4.02 0.0177
2 -3.87 0.0205
3 -3.64 0.0256
4 -3.87 0.0205
5 -4.17 0.0152
6 -0.986 0.272
7 -1.06 0.257
8 -4.40 0.0122
9 -5.15 0.00574
10 -9.10 0.000112
# ℹ 1,213 more rows
Cutoff
The cutoff (or threshold) in logistic regression is the probability value used to convert a continuous prediction (a number between 0 and 1) into a discrete classification (e.g., TRUE or FALSE)
<- babies |> mutate (pred_y = case_when (pred_p < 0.5 ~ FALSE , >= 0.5 ~ TRUE ))select (babies, low_bwt, pred, pred_p, pred_y) |> head (3 )
# A tibble: 3 × 4
low_bwt pred pred_p pred_y
<lgl> <dbl> <dbl> <lgl>
1 FALSE -4.02 0.0177 FALSE
2 FALSE -3.87 0.0205 FALSE
3 FALSE -3.64 0.0256 FALSE
Confusion Matrix
:: tabyl (babies, low_bwt, pred_y) |> :: adorn_totals (c ("row" , "col" ))
low_bwt FALSE TRUE Total
FALSE 1161 5 1166
TRUE 53 4 57
Total 1214 9 1223
The rows show the observed data and the columns show the predicted data.
Sensitivity (true-positive rate): \(\frac{4}{57} = 0.0701754\) Specificity (true-negative rate): \(\frac{1161}{1166} = 0.9957118\) Accuracy : \(\frac{4 + 1161}{1223} = 0.9525756\)